Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLMs
Jingcheng Niu, Xingdi Yuan, Tong Wang, Hamidreza Saghir and Amir H. Abdi.
ACL 2025
We present a mechanistic investigation of LLM distraction. The core idea is simple:
- Contextual Entrainment: LLMs give higher probability to tokens that previously appeared in the prompt, even if those tokens are random or irrelevant.
- Counterfactual context prompts can exacerbate the the entrainment.
- Entrainment Heads: We can identify a set of attention heads (the entrainment heads) that are corresponds to the entrainment of a given pattern, using a differentiable-masking-based method.
Our work marks a key step towards the mechanistic analysis and mitigation of the distraction problem.
 Paper
Paper GitHub
GitHub Talk
TalkTable of Contents
Open Table of Contents
- Background: Distraction
- Context Entrainment
- Finding 1: Contextual Entrainment: LMs assign higher logits and probabilities to tokens that appear in the context.
- Finding 2: “Distracting” context prompts can be beneficial when relevant.
- Finding 3: Counterfactual context prompts consistently cause stronger distraction than factual context prompts.
- Entrainment Heads
- Conclusion
- How to Cite
Background: Distraction
LMs are susceptible to distractions caused by contextual information in prompts.
For example, the model can confidently answer a question Greece is located on the continent of ___.
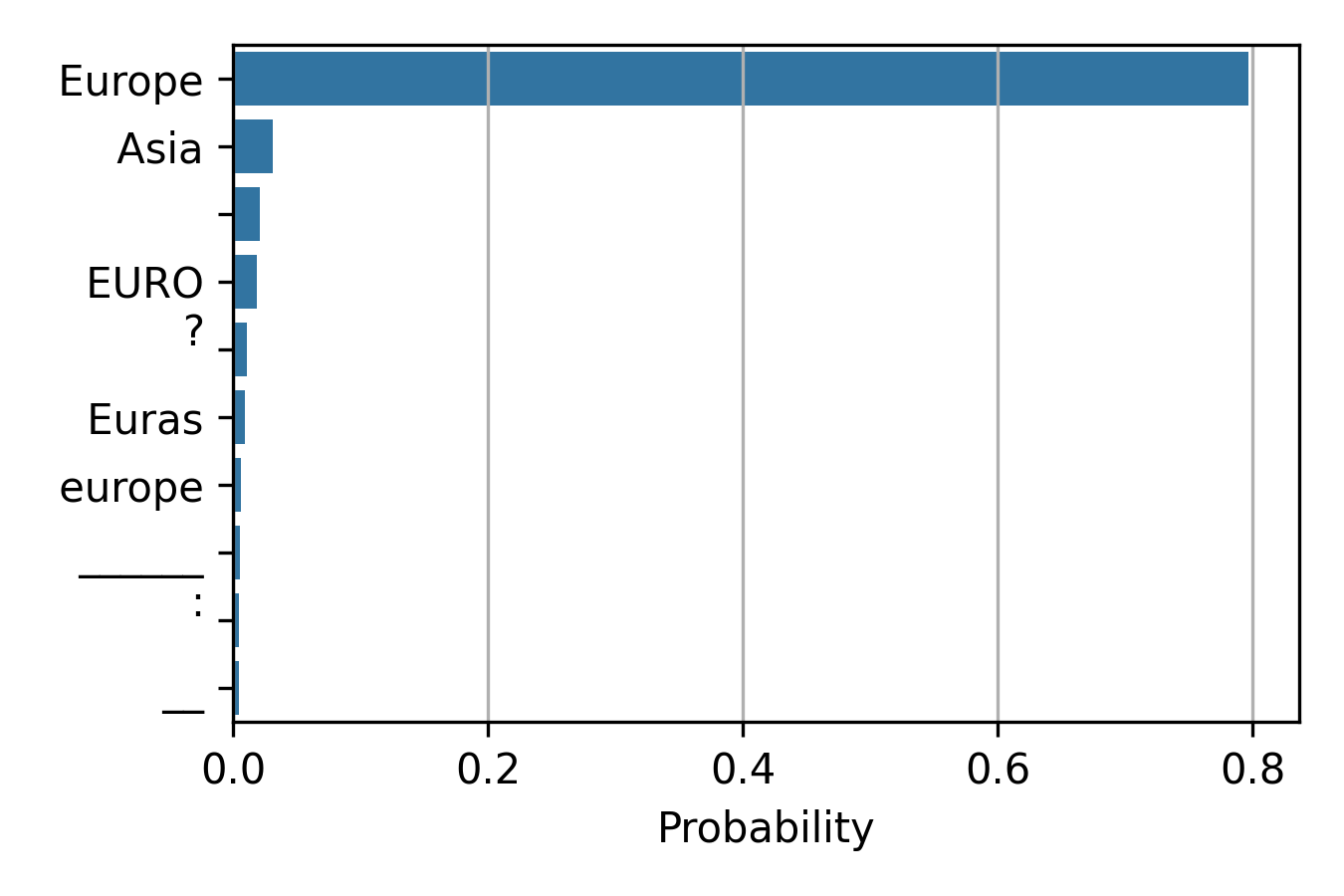
Input prompt: QUERY: Greece is located on the continent of. The figure shows the probability of its top 10 output tokens. The model can confidently answer the question correctly.
However, a piece of distracting context, such as Japan is in Asia. can through the model off track, leading it to assign the highest probability to the wrong answer, Asia.
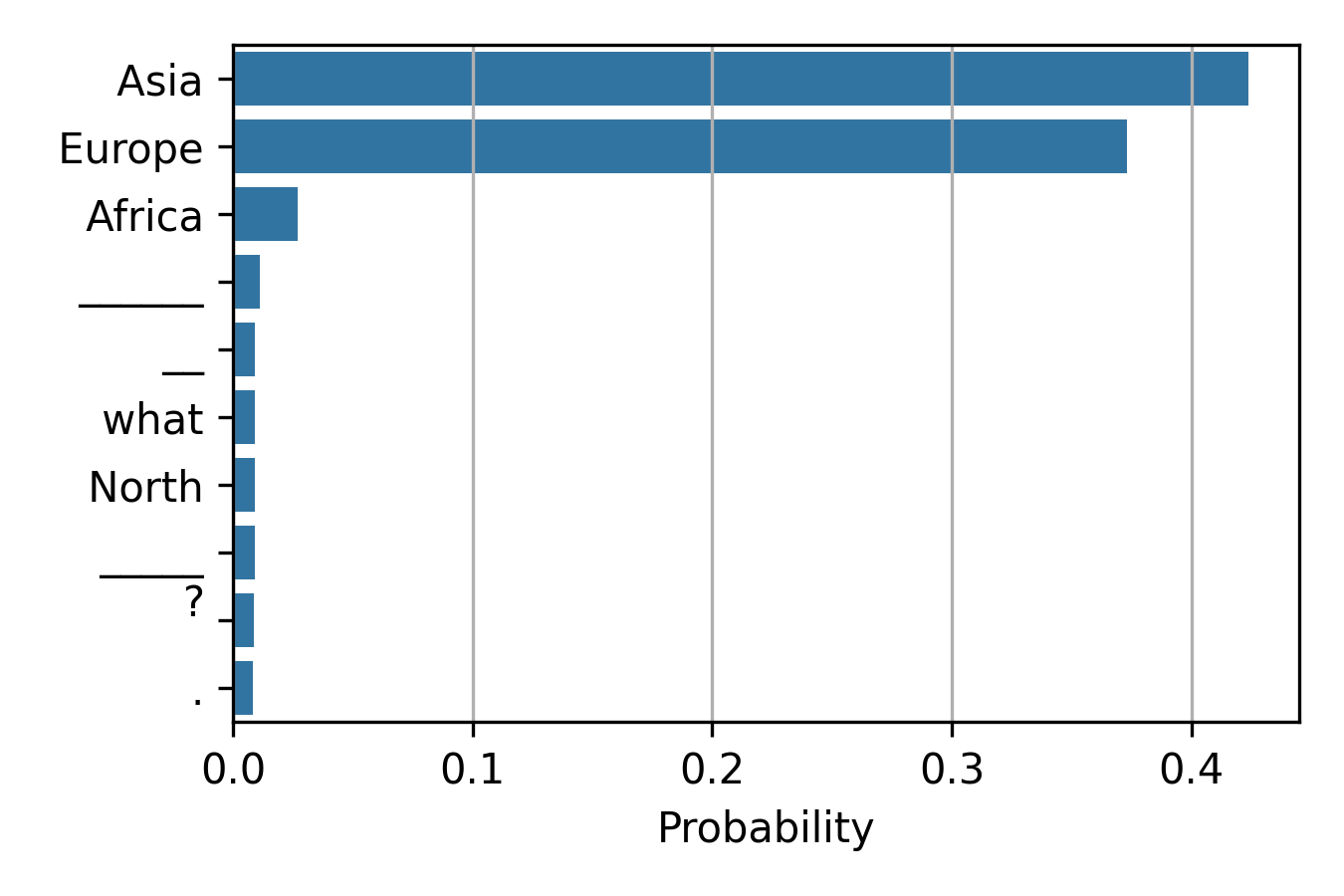
Input prompt: CONTEXT: Japan is in Asia. QUERY: Greece is located on the continent of. Again, the figure shows the probability of its top 10 output tokens. The model can become distracted by the “irrelevant” context and incorrectly assign the highest probability to the wrong answer, Asia.
This also holds for other prompts and context settings. The model may not assign the highest probability to the distracting token, but it still assigns a higher probability to it than warranted.
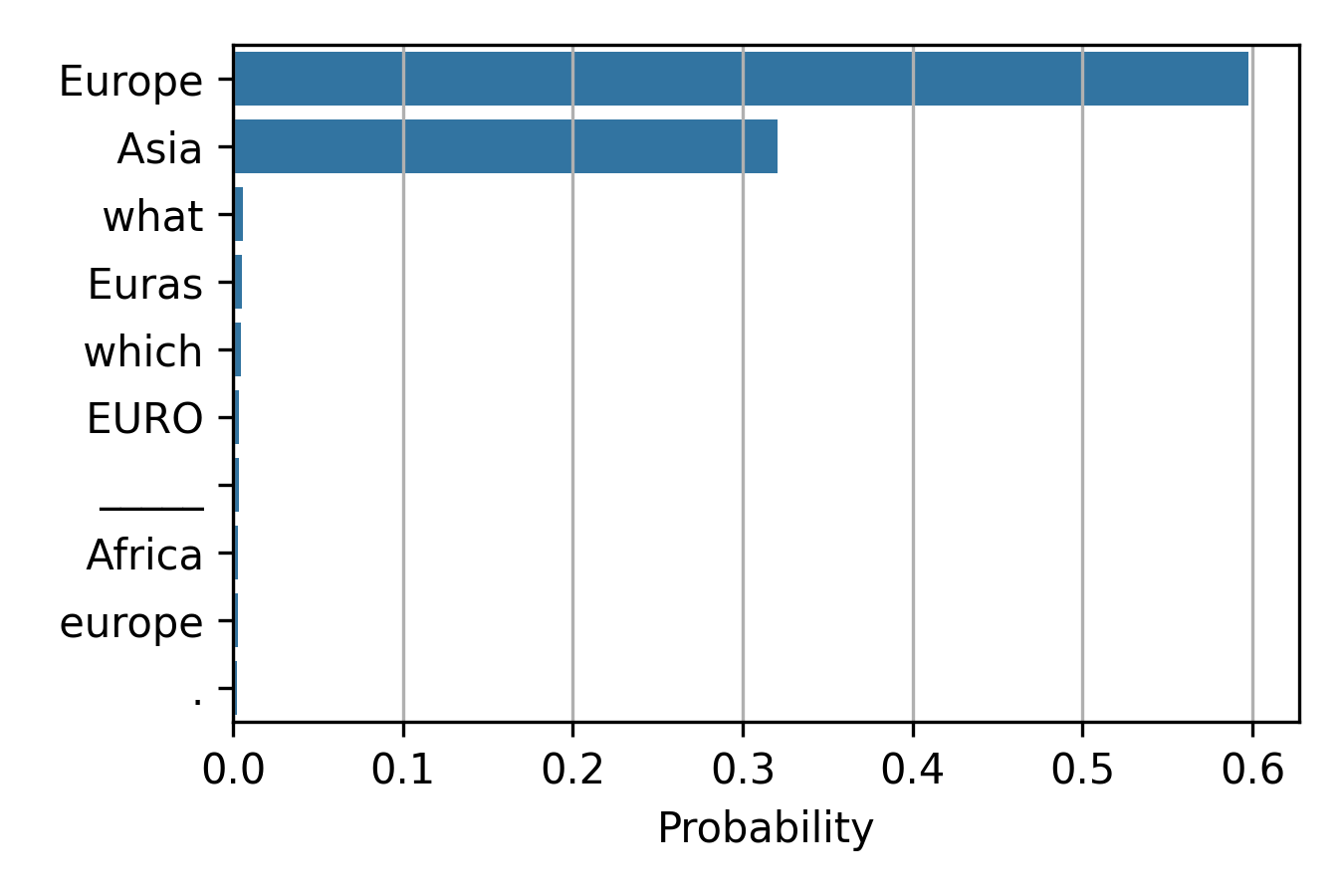
CONTEXT: Asia is the largest continent in the world by both land area and population. QUERY: Greece is located on the continent of
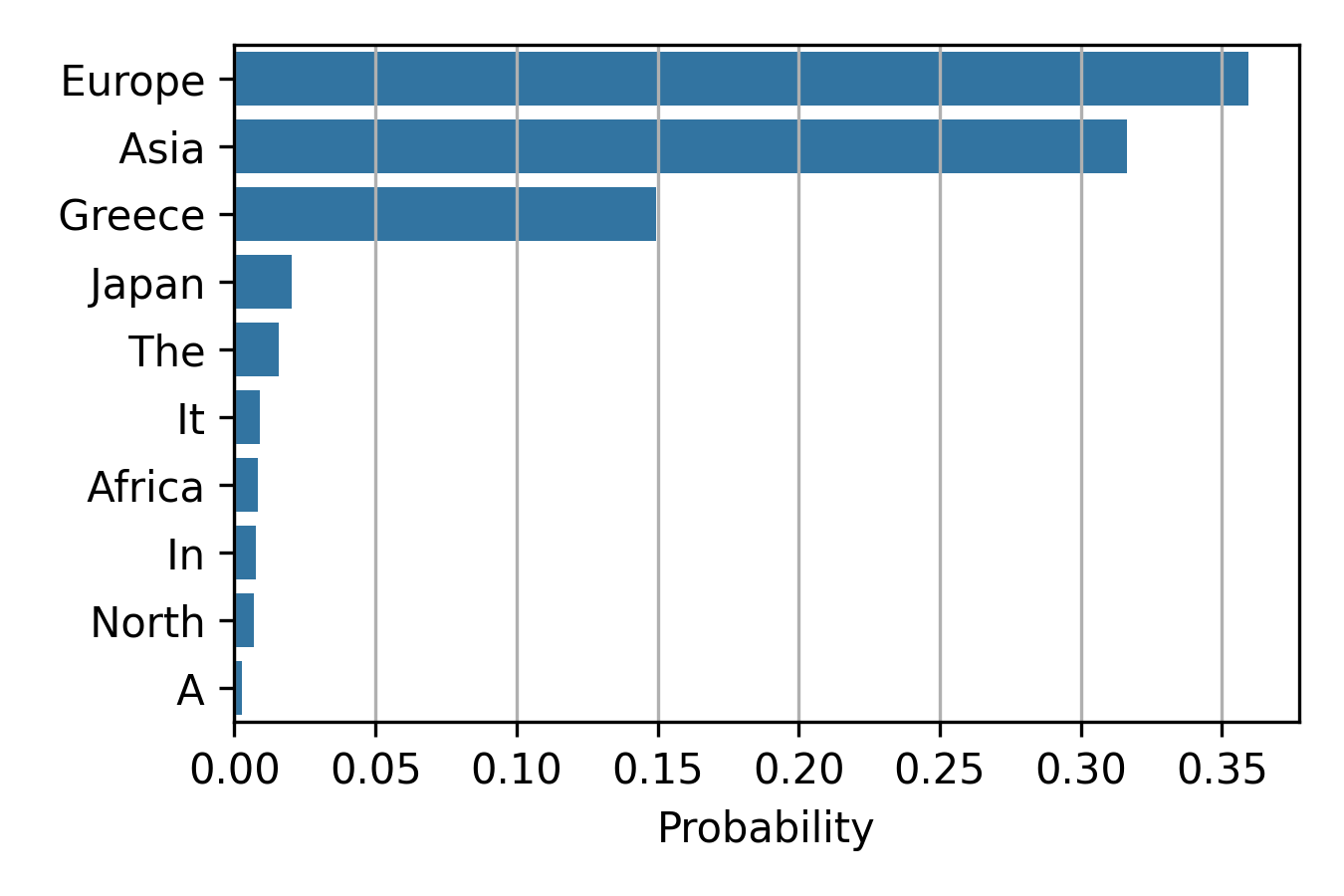
CONTEXT: Japan is in Asia. QUERY: Greece is located on which continent? ANSWER:
Shi et al. (2023) was one of the first to discover the distraction phenomenon. They found that while LMs can accurately solve grade-school maths problems, they may fail when provided with additional information in the prompt. They, however, did not explore the mechanisms underlying these distractions. More research has since confirmed that LMs can be easily distracted (Yoran et al., 2023; Wu et al., 2024; Cuconasu et al., 2024, inter alia). This problem has received remarkable attention in the RAG community due to its apparent connection to retrieval robustness. Since retrievers cannot always retrieve perfectly relevant documents, the LLM within a RAG system should be as resistant to distraction as possible.
Most prior work defines distraction using the term “(ir)relevant,” framed in RAG and information retrieval terms; i.e., whether the context prompt contains the information needed to answer the question correctly. While this provides an adequate general description of the problem, we identify challenges when examining it in greater detail. First, relevance is too broad a concept. Consider the following context prompts: (1) Messi is a football player, (2) Japan is in Asia, (3) Greece is in Asia, and (4) Colorless green ideas sleep furiously. According to the earlier definition, all of these are “irrelevant” since they do not contain the information needed to correctly answer the question Greece is located on the continent of ___. However, it is evident that they differ drastically in how they might influence an LM’s response.
Context Entrainment
Regardless of the debate on the precise definition of distraction, we observe a phenomenon in LMs related to how they use and misuse information from the context prompt. In particular, we identify contextual entrainment: LMs consistently assign significantly higher probabilities (or logits) to any tokens that have appeared earlier in the context prompt, regardless of their relevance or semantic relation to the question or the prompt. Simply put: llama see, llama do. If a token appears in the context prompt, even a random one, the model assigns it a higher probability or logit. Our experiments show that various LMs exhibit contextual entrainment across a wide range of configurations.
Experimental Setup: We provide the model with two types of input: (1) without context, and (2) with context; and three context types: related, irrelevant, or random (counterfactual (😈) cases will be discussed in the next part). We observe the output (logit or probability) of the correct (😊) and the distracting (😵💫) token.1

Finding 1: Contextual Entrainment: LMs assign higher logits and probabilities to tokens that appear in the context.
Now, here is the results for three types of distracting contexts.

Average logits for different tokens across prompt settings. The colour indicates the token type (blue:😊, orange:😵💫), and the shade indicates the context setting (light: with context, dark: w/o context). Observation: The logits of the 😊 tokens increase in the relevant↑ setting and decrease in the irrelevant↓ and random↓ settings, while the logits of the 😵💫 tokens increase across all settings↑.

Now, let us zoom in on the magnitude of the increase or decrease: the difference in logits with or without the context. Again, colour indicates token type (blue:😊, orange:😵💫). Observation: The direction of change confirms the previous observation. Notably, the magnitude of change for the 😵💫 tokens is greater than that of the 😊 tokens.
When a model is given distracting context, there is a significant increase in the logits and probabilities of the corresponding distracting tokens. For example, when asked the question Greece is located in ___, distracting context prompts such as Japan is in Asia, Bananas are yellow, or even a single randomly sampled token, Promotion, can cause the model to assign higher logits to the distracting tokens: Asia, yellow, and Promotion, respectively. When normalised with softmax, logit increases translate into higher probabilities.

:
:
The results observed in the logits carry over to the probability space. This subfigure shows the relative difference in probability. After applying softmax, we observe the same trend as in the logits.
Finding 2: “Distracting” context prompts can be beneficial when relevant.
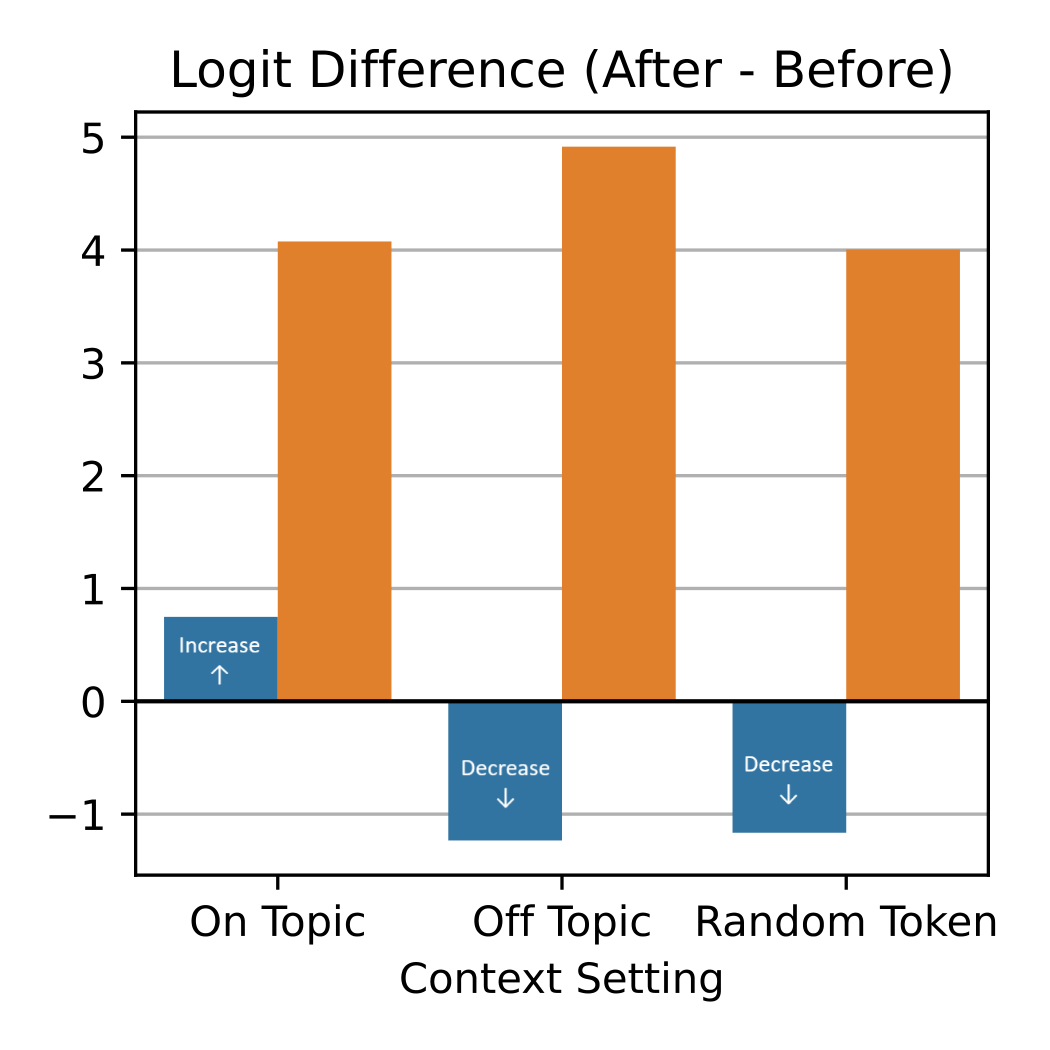
While the probabilities and logits of the distracting tokens (😵💫) consistently increase, the direction of change for the correct token (😊) varies based on the context type.
Again, The logits of the 😊 tokens increase in the relevant↑ setting and decrease in the irrelevant↓ and random↓ settings.
While prior work typically groups “irrelevant context” into a single category and treats it as detrimental, our findings suggest the need for a more nuanced classification. Although distracting context may not contain the exact correct answer, the implicit hints it provides can be beneficial, increasing the likelihood that the model generates the correct response.

Providing “distracting” yet relevant context can be beneficial. For instance, when a question is ambiguous, such context may help clarify its intended meaning or guide interpretation. For example, when the “distracting” context (In Russia, the primary language is Russian) is provided, Llama3.1-8B’s top responses to the prompt In Argentina, people speak the language of shifted from love and football to the language-related tokens: Spanish, Spain and Cast (the first wordpiece of “Castilian Spanish”).
Finding 3: Counterfactual context prompts consistently cause stronger distraction than factual context prompts.
We present the model with two types of distracting context prompts: a factual one (Japan is in Asia) and a counterfactual one (Japan is in Africa). Following the context prompt, we query the LM with a question (Greece is located in ___) and observe how it changes the logits and probabilities of the counterfactual 😈 token (Africa), the distracting 😵💫 token (Asia), and the correct 😊 token (Europe).
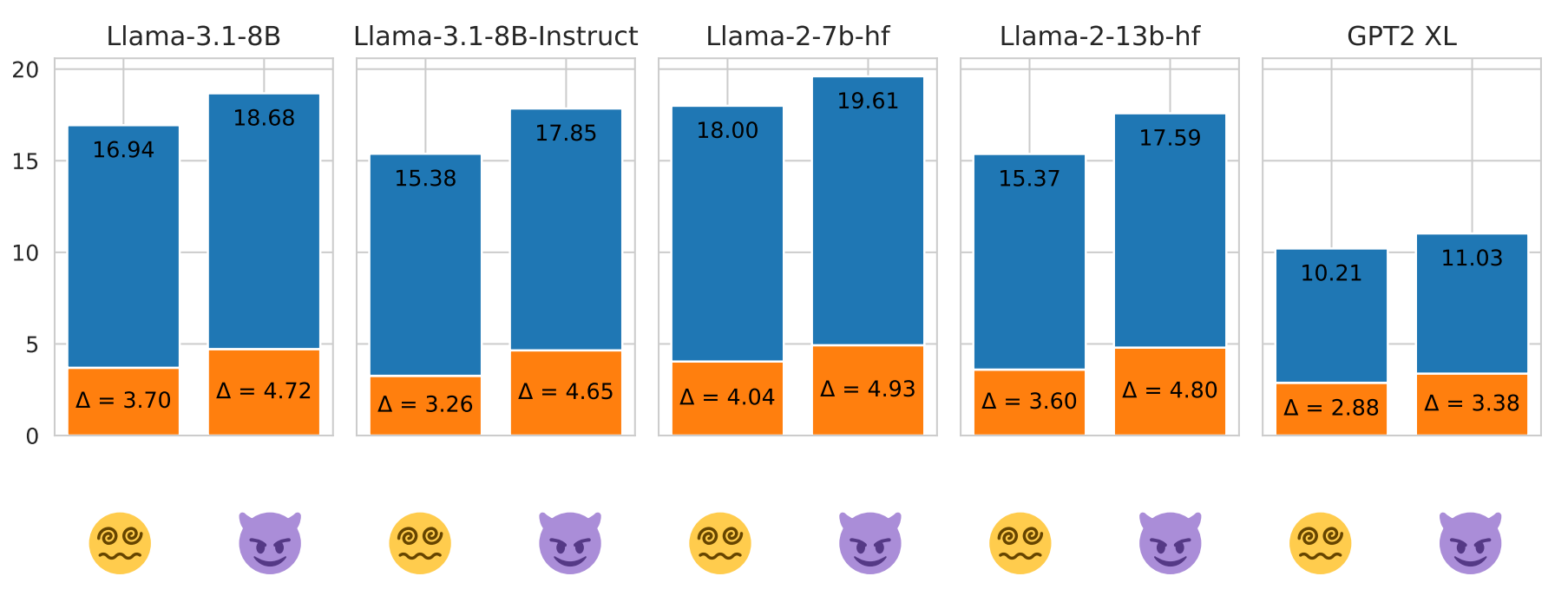
Counterfactual context prompts consistently cause greater distraction than factual context prompts.
The effect of distraction — in other words, the magnitude of contextual entrainment — is stronger for counterfactual context prompts than for factual prompts. This is evident because the absolute logits of the 😵💫 token when factual prompts are provided are significantly lower than those of the 😈 token when counterfactual prompts are provided (height of the blue bars). Moreover, the extent of change is greater for counterfactual prompts: with a factual prompt, the token’s logits increase only slightly compared to no context, whereas a counterfactual prompt causes a much larger increase. This shows that counterfactual prompts create stronger distractions and greater shifts in the model’s output (orange bar height).
Using these counterfactual context prompts results in a significantly stronger impact compared to previously identified factual context prompts. This suggests that, while we previously established that contextual entrainment is a “mechanistic” phenomenon, it is still subject to semantic factors in determining its magnitude of impact.
Furthermore, the fact that counterfactual prompts can cause stronger effects in contextual entrainment suggests that current models are particularly vulnerable to distraction from such inputs. This highlights the potential threat posed by dis- and misinformation.
Entrainment Heads
So… where and how does this contextual entrainment happen? We identify a set of attention heads that corresponds to the contextual entrainment phenomenon, which we call entrainment heads, using a differentiable-masking-based method.
Inspired by DiscoGP (Yu et al., 2024b), we propose an automatic method to identify attention heads corresponding to contextual entrainment for each task configuration. We “turn off” specific heads by setting their contribution to the residual stream to zero. To achieve this, we introduce a binary mask for each head , which selectively activates or deactivates heads (). This mask is made differentiable by converting the sampled variable from a Gumbel-sigmoid distribution using the straight-through estimator (Bengio et al., 2013). Please see the paper for more details.
Our algorithm identified 36 entrainment heads for the country—capital city relation.
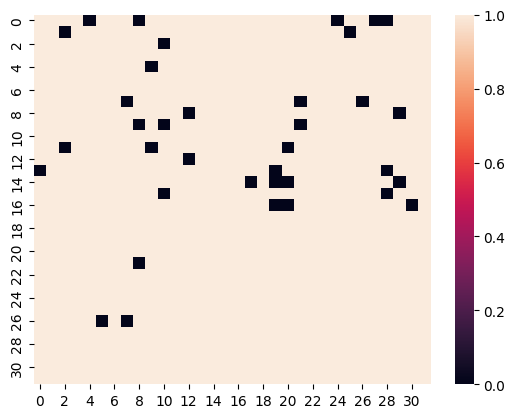
The 36 identified entrainment heads for country—capital city.
”Turning off” the entrainment heads drastically reduce contextual entrainment.
When “turning these entrainment heads off,” i.e., setting their output to zero, the model attenuates the effect of contextual entrainment.
Normally, the mode is distracted by the counterfactual context The capital city of Germany is Moscow, confirming our previous findings.
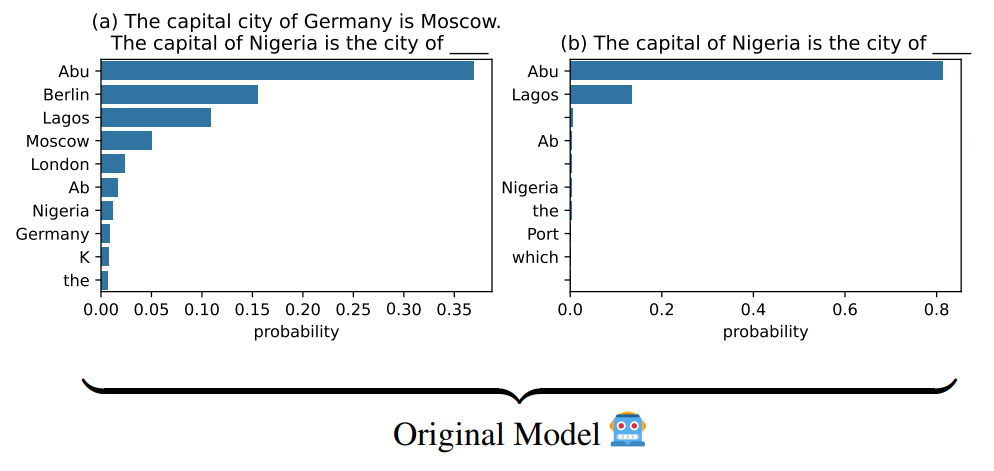
(a,b) In the original model, when a piece of counterfactual information is presented, the model assigns higher probabilities to the distractions: Berlin and Moscow.
However, after “turning off” the entrainment heads, the contextual entrainment effect is substantially attenuated. The rankings of the tokens Berlin and Moscow dropped from 2nd and 4th to 53rd and 68th, respectively. Additionally, the difference in logits between the correct 😊 token (Abu)2 and the distracting 😵💫 tokens (Berlin and Moscow) increased from 0.86 and 2.00 to 7.54 and 7.79, respectively.
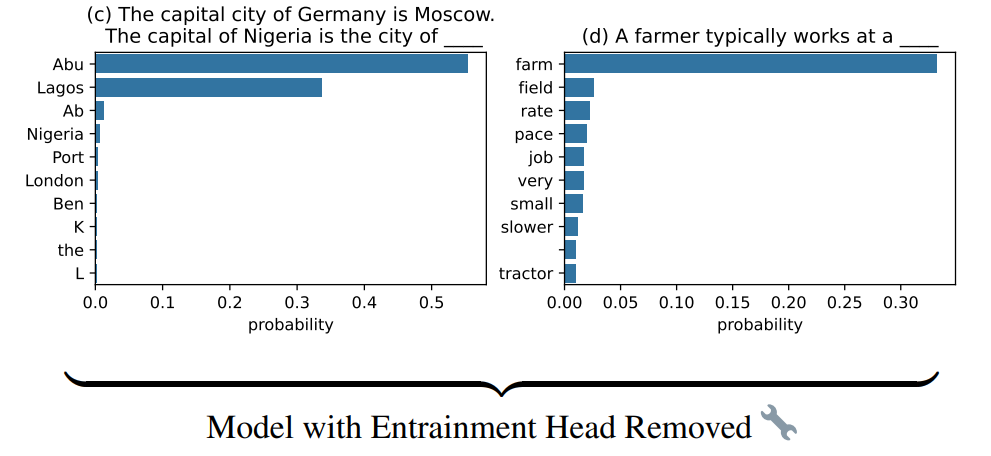
(c) After setting the output of the identified entrainment heads to zero, however, the effect of contextual entrainment is drastically attenuated. (d) This operation of removing the entrainment heads has only a small impact on other capabilities; the model can still correctly answer questions in other domains.
This attenuation is not a fluke. Removing the entrainment heads significantly shifts the logits difference, probability difference, and the ranks of the distracting tokens towards the values observed when no distracting context is provided, across the entire country—capital city relation test set.
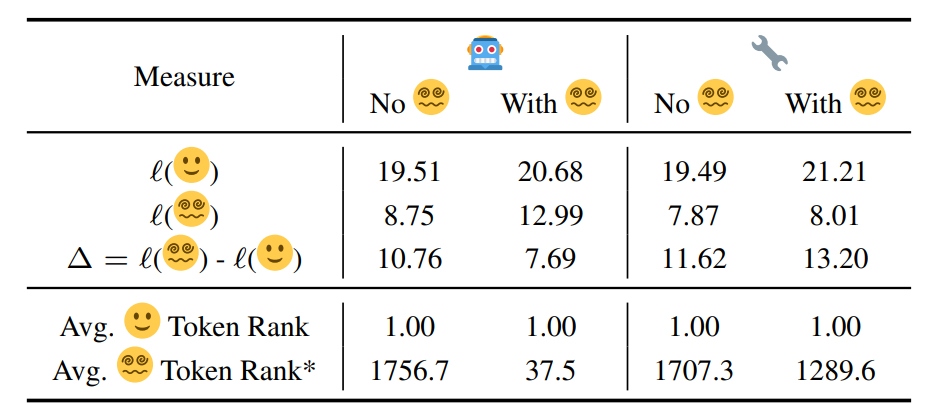
Removing the entrainment heads caused a significant effect across logits delta and the ranks of the 😵💫 tokens, making them capitulate the situation when no distracting context is provided. *: according to paired t-tests conditions between 🤖 and 🔧.
Entrainment heads are task-specific (or relation-specific), not model-specific.
Again, as we have shown, our method has identified different and different amount of entrainment heads for each LRE relation. This suggests that the entrainment heads are task-specific (or relation-specific), rather than model-specific.
Removing the entrainment heads has only a small effect on other LM capabilities.
While removing the entrainment heads significantly impacts contextual entrainment, it has only a negligible to small effect on other LM capabilities. First, we use other relations from the LRE dataset to evaluate whether the LM can still interpret the query and recall factual information, as well as perform ICL.
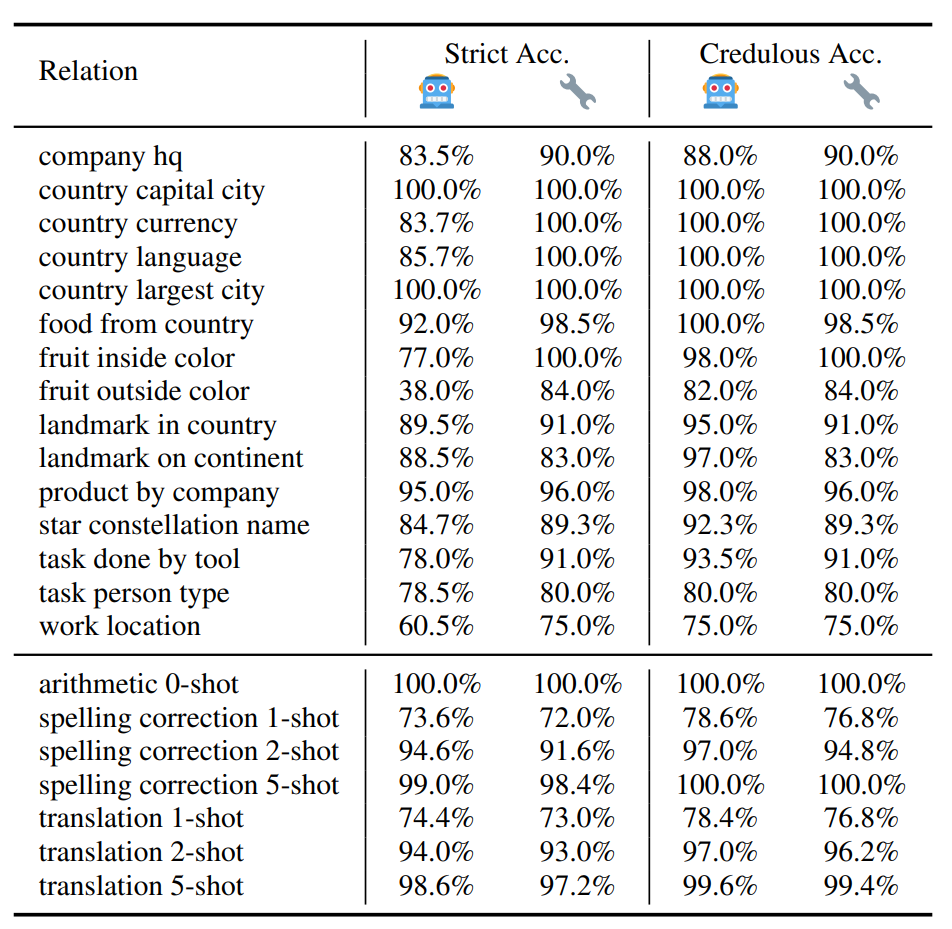
Removing the entrainment heads of the country– capital city relation has a small to negligible effect on other LM capabilities. This table compares the strict (answer in top-3) and credulous (answer in top-10) accuracy of the original model (🤖) and the model with country—capital city entrainment heads removed (🔧). Removing these heads has a negligible effect on the LM’s performance across other relations, with no obvious differences between 🤖 and 🔧.
This finding supports our hypothesis that this “circuit” of entrainment heads collectively corresponds to contextual entrainment rather than other capabilities and phenomena, such as factual recall, and is not strongly related to how LMs process and utilise contextual information or perform ICL more broadly. Thus, contextual entrainment and its connection to entrainment heads provides a novel perspective for understanding distraction.
Conclusion
Llama see, llama do. We observe and confirm a novel phenomenon, which we term contextual entrainment. If a token has appeared previously in the prompt, the model assigns a higher logit to that token, even for random tokens. Thus, a novel mechanistic effect may be at play in governing how LMs process and utilise information from the prompt — an effect that is analogous to but distinct from previously identified phenomena, such as the inductive literal sequence copying effect observed by Olsson et al.’s (2022). However, we also discover that contextual entrainment is influenced by semantic factors. This finding highlights the potential threat of dis- and misinformation, which may be more severe than mere mistakes generated by the model. It also suggests that there may not be a strict dichotomy between mechanistic and statistical interpretations of LMs. Our identification of the entrainment heads suggests that interpretability techniques could provide crucial insights for real-world applications, such as the study of distraction.
How to Cite
@inproceedings{niu-etal-2025-llama,
title = "Llama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in {LLM}s",
author = "Niu, Jingcheng and
Yuan, Xingdi and
Wang, Tong and
Saghir, Hamidreza and
Abdi, Amir H.",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.acl-long.791/",
pages = "16218--16239",
ISBN = "979-8-89176-251-0"
}Footnotes
-
Prompts are generated using facts from the LRE dataset (Hernandez et al., 2024). For the sake of brevity, we only present the results using
Llama-3.1-8Bin this blog post. We experiment withGPT2 XL(Radford et al., 2019) and 4 LLaMA models (Touvron et al., 2023):Llama-3.1-8B,Llama-3.1 -8B-Instruct,Llama-2-7b-hf, andLlama-2-13b-hf. Those results are available in the paper. ↩ -
“Abu” is the first wordpiece of Abuja, the capital city of Nigeria. ↩